



Llega Mistral Small 4, un solo modelo para razonar, programar y analizar imágenes, con menos coste que la competencia
por Edgar OteroMistral AI, que recientemente se asoció con ASML, acaba de presentar Mistral Small 4, el nuevo modelo de la familia Small que unifica en un único sistema las capacidades que hasta ahora estaban repartidas entre productos especializados. Primero, Magistral para razonamiento complejo. Luego, Devstral para programación agéntica y, finalmente, Pixtral para análisis de imágenes. La propuesta es sencilla: un solo modelo que se adapta a la tarea en lugar de obligar al desarrollador o la empresa a elegir entre varias opciones según el caso de uso.
Como ya sucede con otros modelos de la compañía, el modelo se publica bajo licencia Apache 2.0, lo que significa que cualquiera puede descargarlo, modificarlo, ajustarlo con datos propios y desplegarlo en producción sin restricciones comerciales. En un momento en el que varias empresas del sector están endureciendo las condiciones de uso de sus modelos abiertos, Mistral mantiene su apuesta por la apertura total, incluyendo pesos del modelo disponibles en Hugging Face desde el primer día.
La arquitectura que explica su eficiencia: muchos expertos, pocos activos
Para entender por qué Mistral Small 4 puede ser eficiente a pesar de su tamaño, hay que comprender cómo funciona su arquitectura de Mixture of Experts, o MoE. En lugar de activar todos los parámetros del modelo para cada consulta, como hacen los modelos densos tradicionales, un sistema MoE divide el trabajo entre muchos submodelos especializados llamados "expertos" y activa solo los más relevantes para cada fragmento de texto procesado.
En el caso de Small 4, el modelo cuenta con 128 expertos en total, pero solo activan 4 de ellos por cada token procesado. El resultado es un modelo con 119.000 millones de parámetros totales, pero que en la práctica opera con apenas 6.000 millones activos en cada inferencia (8.000 millones contando las capas de embedding y salida). Esto permite mantener la capacidad y el conocimiento acumulado de un modelo grande mientras se ejecuta con el coste computacional de uno bastante más pequeño.
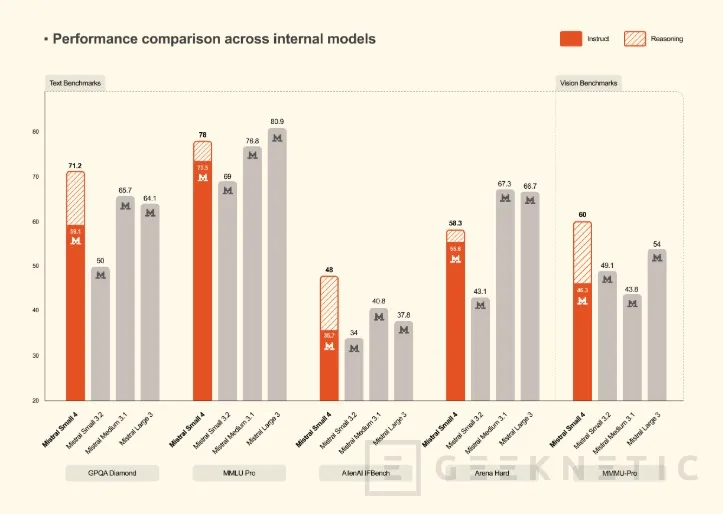
Las consecuencias prácticas son directas: Mistral afirma una reducción del 40% en el tiempo de respuesta extremo a extremo en configuraciones optimizadas para latencia, y hasta tres veces más peticiones por segundo en configuraciones optimizadas para rendimiento, comparado con Mistral Small 3. La ventana de contexto llega a los 256.000 tokens, suficiente para procesar documentos largos o mantener conversaciones extendidas sin perder coherencia.
Razonamiento configurable y multimodalidad nativa
Una de las novedades más relevantes es el parámetro reasoning_effort, que permite al desarrollador controlar en tiempo real cuánto "esfuerzo" dedica el modelo a razonar antes de responder. Con el valor none, el modelo funciona como un asistente conversacional rápido, equivalente en comportamiento a Mistral Small 3.2. Con el valor high, activa un modo de razonamiento paso a paso comparable al de los modelos Magistral, pensado para matemáticas, análisis complejos o tareas de investigación.
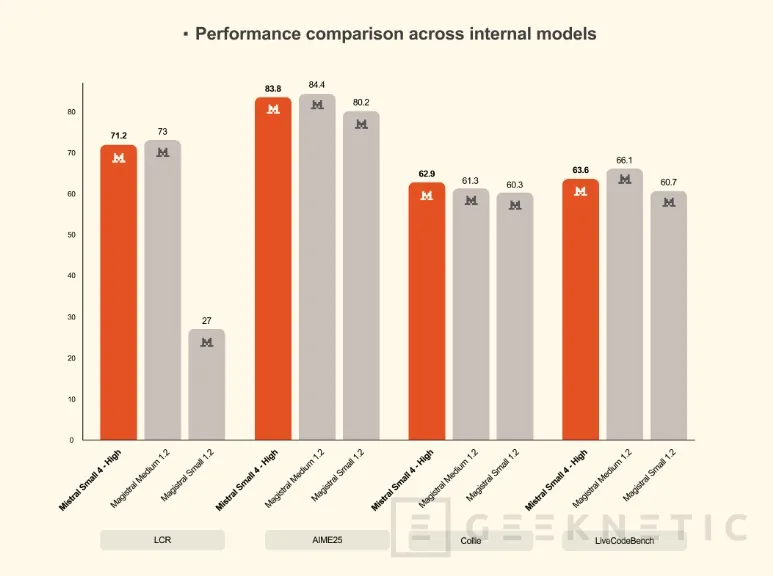
Esta flexibilidad permite usar el mismo modelo tanto para responder preguntas simples de forma instantánea como para resolver problemas que requieren cadenas de razonamiento largas, sin cambiar de herramienta ni gestionar múltiples endpoints en producción.
El soporte multimodal, por su parte, es nativo: el modelo acepta tanto texto como imágenes como entrada, lo que abre casos de uso como el análisis de documentos escaneados, la interpretación de gráficos o la descripción de contenido visual dentro de flujos de trabajo automáticos.
Más rendimiento con menos palabras que la competencia
El argumento competitivo de Mistral Small 4 no se apoya solo en las puntuaciones de los benchmarks, sino en la relación entre rendimiento y longitud de respuesta, un indicador que tiene implicaciones económicas directas. En las pruebas publicadas por la compañía, el modelo iguala o supera a GPT-OSS 120B de OpenAI en los tres benchmarks evaluados (AA LCR, LiveCodeBench y AIME 2025), generando respuestas notablemente más cortas.
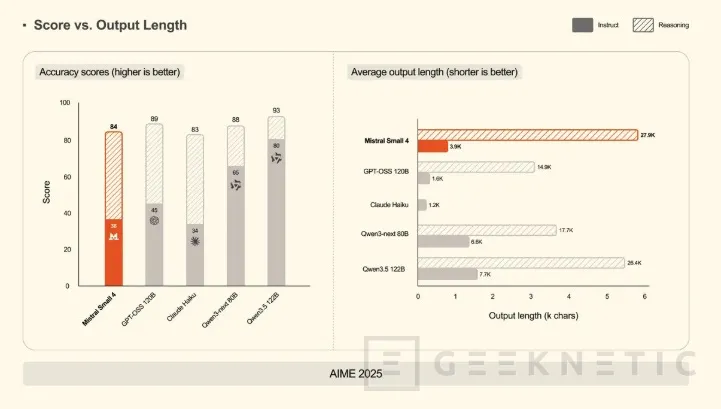
El contraste con los modelos de la familia Qwen es especialmente llamativo: en el benchmark AA LCR, Mistral Small 4 alcanza una puntuación de 0,72 con una respuesta media de 1.600 caracteres, mientras que los modelos Qwen comparables necesitan entre 5.800 y 6.100 caracteres para resultados similares, entre tres y cuatro veces más. En LiveCodeBench, Small 4 supera a GPT-OSS 120B generando un 20% menos de texto.
Para equipos técnicos y empresas que despliegan modelos a escala, esto se traduce directamente en menos tokens facturados, menor latencia percibida por el usuario y menor presión sobre la infraestructura. Respuestas más cortas con igual o mejor precisión reducen también la necesidad de sistemas de validación adicionales o intervención manual para tareas críticas.
En cuanto al hardware necesario para despliegue propio, Mistral indica como mínimo 4 unidades NVIDIA HGX H100, 2 NVIDIA HGX H200 o 1 NVIDIA DGX B200. La configuración recomendada dobla esas cifras para rendimiento óptimo. El modelo ya está disponible en la API de Mistral, en AI Studio, en Hugging Face y como NVIDIA NIM para despliegue en contenedores optimizados desde el primer día.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







